Chatting locally
I’ve been testing different large language models (LLMs) lately, and wanted to write a small guide on how to run a LLM locally on your machine. There are actually several models which will work nicely just by using your computer’s CPU. The set up is pretty straightforward.
What do we need?
There are different ways to run a LLM locally, but I will show you how to do it using Docker and Ollama. Ollama is a lightweight framework that allows you to run different language models locally. The Ollama website lists a large number of models that you can access.
It is possible to install Ollama directly on your computer, but you can also use Docker to run it. First, we need to pull the official image from Docker Hub.
docker pull ollama/ollamaAfter this we can run the image using the following command:
docker run -d -p 11434:11434 --name ollama ollama/ollamaThis will start the Ollama server inside a Docker container. You can now access the server using the following URL: http://localhost:11434/. Your web browser should display a simple message stating Ollama is running if you visit the URL. This signals that everything is working as it should and the system is up and running on our machine.
We can now use Ollama to interact with the LLM on the command line. Use the following command to start a chat with the llama2 model:
docker exec -it ollama ollama run llama2This will first pull the model to your docker container, and start a chat with the llama2 model. Chatting with the model is done by typing messages on the command line. Ollama is using your computer’s CPU to run the model, so it will not be as fast as ChatGPT, but it will be completely private. It is also possible to run the model on a GPU if you happen to have a new Nvidia GPU for example.
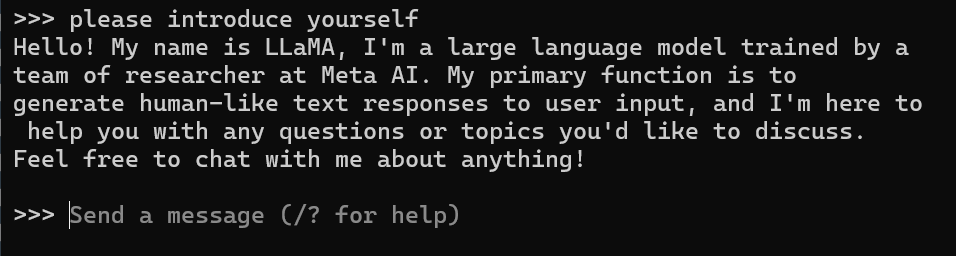
You can replace llama2 with any of the models listed on the Ollama website. The website also gives information on the memory requirements for some models. You can also stop and restart your container without having to re-download the LLM. However, if you remove your container, you will naturally have to download the language model again when starting new containers.
Creating a simple GUI with Python
Now that we are successfully running a LLM locally, we can create a simple GUI to interact with the model. I will show you how to do this using Python and Streamlit.
Setting up a conda environment
I’ve been using the Anaconda distribution for Python, so I will show you how to set up a conda environment for this project. Let’s head to the terminal and write:
conda create --name local-llms -c conda-forge langchain streamlit
conda activate local-llms
pip install langchain_communityThis should provide you with a local-llms conda environment with the necessary Python libraries installed. Next, we will need to create a simple Python script to interact with the LLM.
Creating a simple Streamlit app
Let’s start by creating a file called app.py, which will contain our Streamlit app (the name of the file can be my-fancy-app.py or whatever you want, but app.py seems to be the convention). The contents are fairly simple:
import streamlit as st
from langchain_community.llms import Ollama
# Initialize the Ollama object
ollama = Ollama(base_url='http://localhost:11434', model='llama2')
# App Framework
st.title("Ollama Streamlit app with LangChain 🦜🔗")
prompt=st.text_input("Insert in your prompt here")
# Show response on the screen if there is a prompt
if prompt:
response = ollama.invoke(prompt)
st.write(response)You need to have your Docker container up and running for the app to work. Let’s run the app by entering the following command to the terminal:
streamlit run app.pyThis will launch a new tab in your web browser with the Streamlit app. You can now chat with the LLM using a simple GUI as shown in Figure 2.
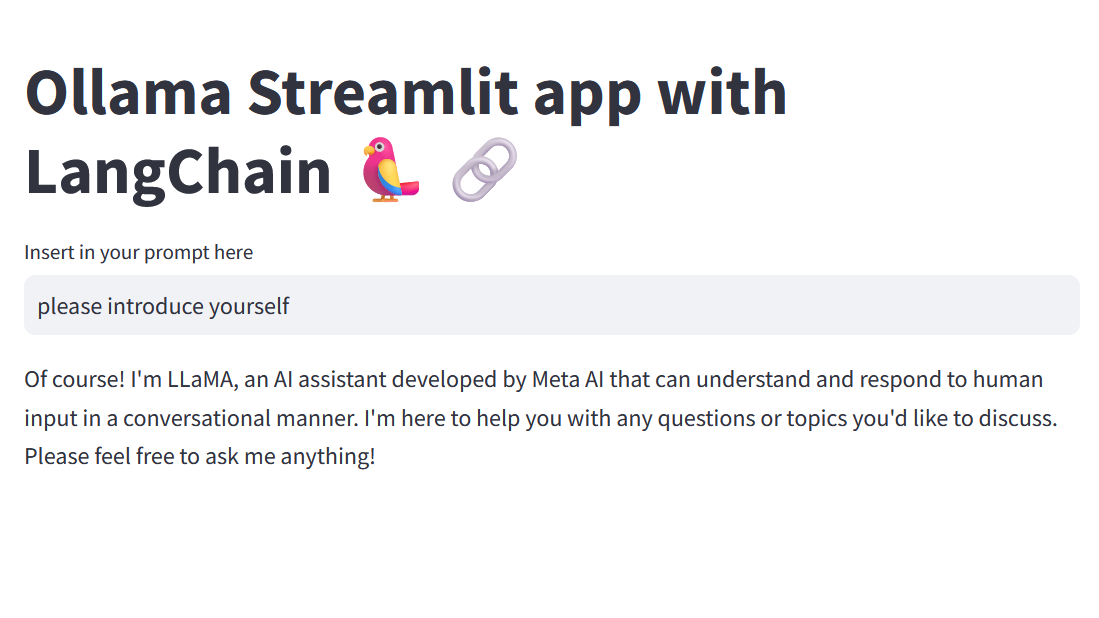
Final thoughts
We saw above how to set up a locally running LLM using Docker and Ollama. We can start building more elaborate app prototypes on top of this setup. Running a LLM locally is a great way to experiment with different models without having to rely on external cloud providers. It is also a good way to keep your data private. Additionally, the environmental impacts of running a LLM locally can be significantly smaller compared to running it on a cloud service.